Big Data Made Small with Heroku, DynamoDB, and Elastic Map Reduce
 One million tweets per day.
One million tweets per day.
An average of fifteen words per tweet.
Four (awesome) days of Dreamforce 2012…
Out of the 60 million words that scrolled across the screen on the Model Metrics Art of Code exhibit Moving the Cloud during Dreamforce 2012, which were the most frequently used? Well, “social” was #1, then “touch” and “mobile”. The word cloud above shows the rest of the top 100. But how did we calculate that? And, more importantly, how can we do so in a way that will easily scale up to working with much larger data sets?
Well, Moving the Cloud is written in Node.js, and I didn’t want to do anything that would tax the production version of the page, so the first thing I did was to create a simplified version of it by stripping out the UI/HTTP layer and adding in the Dynamo package for working with Amazon DynamoDB. DynamoDB is a highly performant, highly scaleable NoSQL database service hosted by Amazon Web Services. Amazon automatically handles scaling the storage space for you with super-fast SSD drives. Your main configuration options are to set the max number of allowed reads per second, and the max number of writes per second. Changing these values takes less than a minute, and you can set up CloudWatch alarms to let you know if you’re getting close to the limits. You pay more for higher limits, and we were seeing around 25-50 tweets per second max, so I set the write limit to 100. The read limit only really matters when you want to start reporting on the data, so I set it pretty low initially.
As you can see from the Trendy-Dynamo code in GitHub, the actual communication with DynamoDB from Node.js is pretty simple. DynamoDB stores Key/Value pairs, and has no defined schema aside from requiring a primary key. The Twitter Streaming API returns JSON documents with a lot of extra cruft, so I pulled out the relavent information and stored in in DynamoDB:
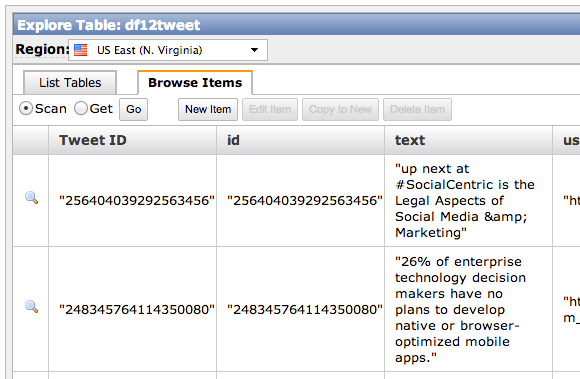
Back in the olden days of aught four, I might have set this running on an old linux box laying around my house (I still actually have a few big towers stacked in the basement, along with boxes of power supplies and old parts, but they haven’t been turned on in ages). Then my ISP would drop the connection, or the power supply would fail, and I’d be missing a bunch of data. Enter Heroku. Such an app can literally be hosted for free on the Heroku Cedar Stack with one Worker Dyno:
Okay, so that’s the initial setup — let’s move ahead a few days — #DF12 is over, and we have 60 million words to count. This is where Elastic Map Reduce (EMR) comes in. EMR is a hosted instance of Apache Hadoop, and Map-Reduce is a handy algorithm for taking huge data sets and breaking them down into smaller, manageable chunks. Think of it like this — imagine in this image that each of the three multi-colored blocks on the left side is one individual tweet…
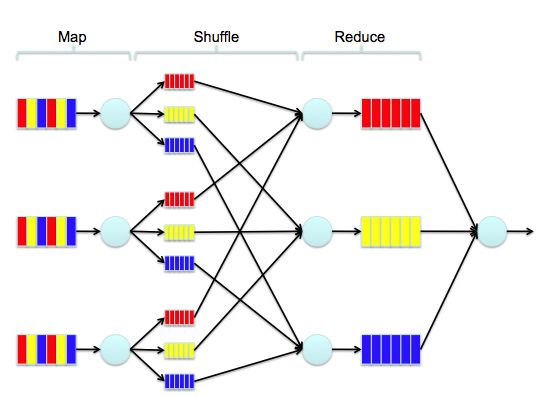
Say the red block is the word “salesforce”, the yellow block is the word “is”, and the blue block is the word “social”. The first step of the process is to count the instances of each word in that tweet. Then, we increment the count of that word in every tweet. Simple, right? Over time, we break down 60 million words into a reduced set where each word occurs only once, but is accompanied by a number that represents the total number of occurrences. To do this with EMR, the first thing we need to do is to snapshot the data from DynamoDB into Amazon S3. To do this, I’ve used an interactive command line Hadoop tool named Apache Hive. It allows you to map external tables and to query them with SQL-like syntax.
Using Hive, I created an external table for DynamoDB:
CREATE EXTERNAL table dynamo_tweet (tweet_id string, tweet_text string)
STORED BY 'org.apache.hadoop.hive.dynamodb.DynamoDBStorageHandler'
TBLPROPERTIES ("dynamodb.table.name" = "df12tweet","dynamodb.column.mapping" = "tweet_id:Tweet ID,tweet_text:text");
And an external table for S3:
CREATE EXTERNAL TABLE s3_df12snapshot (tweet_id string, tweet_text string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION 's3://mm-trendy-dynamo/demo_output/';
And then copy from one to the other:
INSERT OVERWRITE TABLE s3_df12snapshot
SELECT * FROM dynamo_tweet;
Snapshotting takes a little while, so go get a coffee or something… Don’t worry, I’ll wait.
…And, we’re back. Okay, so now we need to actually run the Map-Reduce job to count each word. Luckily, EMR gives us a sample application that does just that:
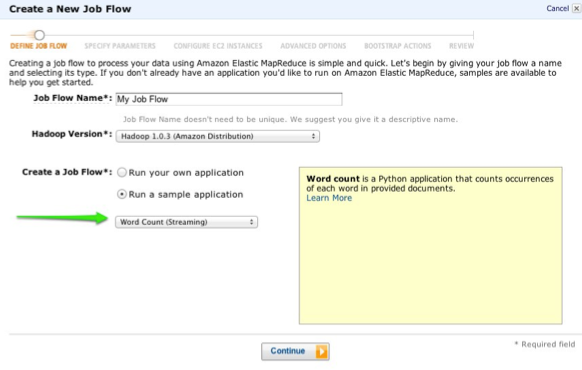
Select the Word Count job, walk through the rest of the wizard, and let it start processing. The amount of time it takes is basically a factor of how many EC2 instances you throw at it, and the processing power of each. When it finishes, the output of the job will be stored in S3, and you can create another external table in Hive:
CREATE EXTERNAL TABLE s3_df12mapreduce (tweet_word string, tweet_count int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 's3://mm-trendy-dynamo/outputmapreduce/';
And then query it:
SELECT * FROM s3_df12mapreduce
WHERE LENGTH(tweet_word) > 4
ORDER BY tweet_count DESC
LIMIT 100;
What you do with this map/reduced data is then up to you, but if you’re interested in how I created the word cloud, I used this D3-Cloud Javascript Library
TL;DR: I made a wordcloud with some tweets.