oAuth 2.0 for Salesforce.com
At this point in time, we’ve implemented the oAuth 2.0 User-Agent flow and the Refresh Token flow for iOS, Android, and Flex/AS3. I figure that makes us as much an expert at doing this as anybody, so I thought I’d take a moment to describe some of the details. First off, the reason you want to use oAuth 2.0 when developing apps for mobile devices… no token. We’ve been developing mobile apps for Salesforce.com for the last 4 or so years, and the need to provide a username, password, and token has always been a pain point. Since it’s a 24 character alpha-numeric string, this was especially problematic back before iPhones had copy/paste functionality (“is that a l, an I or a 1?”). With oAuth 2.0, you can finally get rid of having to worry about the token.
oAuth 2.0 is a popular universal specification for authentication to various web services. If you’ve used a mobile app that logs into Facebook, Twitter, LinkedIn, or Chatter, you’ve probably used it. for Salesforce.com provides four different authentication flows:
- Web Server
- User-Agent
- Refresh Token
- Username/Password
A combination of the User-Agent flow and Refresh Token flow are recommended for mobile applications, so that’s what I’ll demonstrate here.
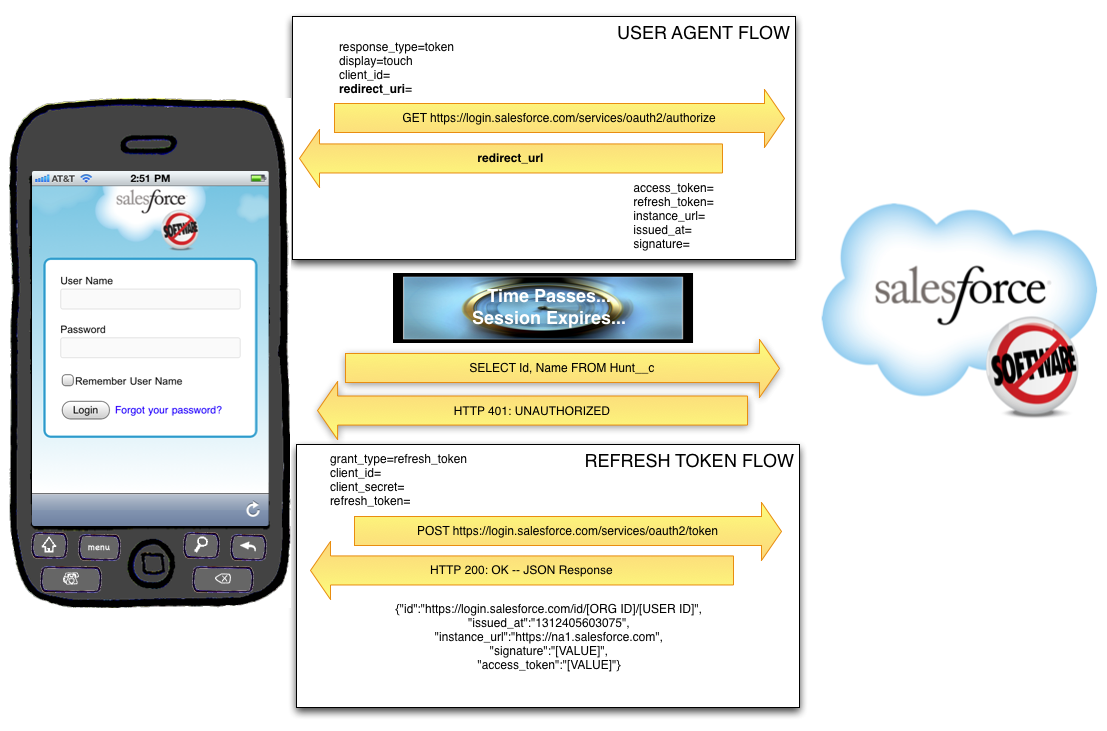
First off, you should understand both flows from a high level:
Salesforce Configuration
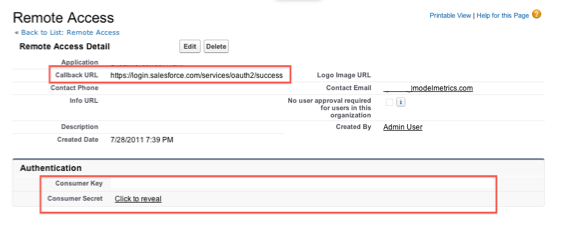
Both the User-Agent flow and the Refresh Token flow require a Remote Access Application be set up in the target SFDC org. This is configured under Setup=>Develop=>Remote Access. Required fields are Application, Contact Email, and Callback URL. There are a variety of rules about what the Callback URL can be, but the simplest way to do this is to have it be: https://login.salesforce.com/services/oauth2/success
Once saved, SFDC will generate and display a Consumer Key and a Consumer Secret. Both of these will be needed by the application for login.
User-Agent Flow
The User-Agent flow involves the use of a webview within the application. The app passes a special Salesforce.com URL to that webview, which renders a login view.
First, the user will be asked to log in, and then they will be asked to confirm that they would like to provide access to Salesforce.com using this application:
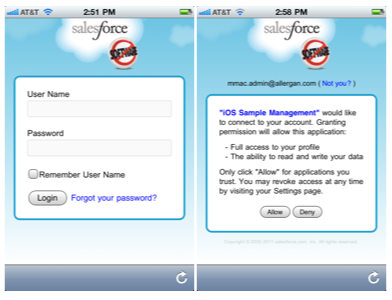
The URL passed to SFDC in order to render this login view is in this format:
https://login.salesforce.com/services/oauth2/authorize?
response_type=token&
display=touch&
client_id=[CONSUMER KEY FROM REMOTE ACCESS]&
redirect_uri=https%3A%2F%2Flogin.salesforce.com%2Fservices%2Foauth2%2Fsuccess
Upon successful login, SFDC will redirect the webview to the URL specified as the redirect_uri (which must be the same as the Callback URL specified in the Remote Access Application setup). After the Callback URL will be a hash tag and then a series of parameters returned by Salesforce:
access_token=[ACCESS TOKEN (Session Id)]
&refresh_token=[REFRESH TOKEN]
&instance_url=https%3A%2F%2Fna1.salesforce.com
&id=https%3A%2F%2Flogin.salesforce.com%2Fid%[ORG ID]%[USER ID]
&issued_at=1312403866216
&signature=[SIGNATURE]
The Access Token specified here is the Session ID that will be used for all subsequent calls to the API. The Refresh Token must be saved securely to disk, as it will be used in conjunction with the Consumer Key and Consumer Secret to get a new Access Token from SFDC when the current on expires. The Org Id, User Id, Issued At Time (number of milliseconds since the Unix Epoch), and Signature should be saved as well.
Refresh Token Flow
At some point in time, your Access Token will expire. This may come as a shock, so be sure to prepare your friends and family. The app will learn that the session ID has expired when it attempts to access the API and the response is either:
- SOAP API: HTTP 500 Internal Server Error, with a faultCode: <faultcode>sf:INVALID_SESSION_ID</faultcode>
- REST API: HTTP 401 Unauthorized
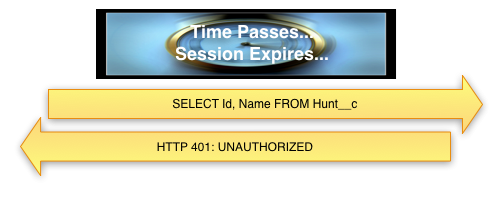
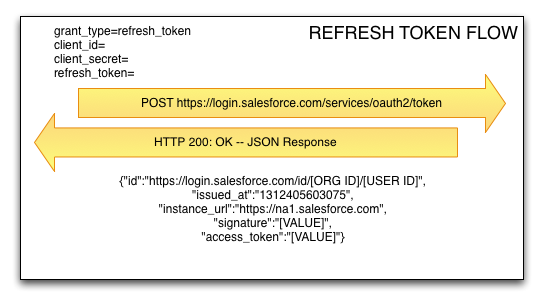
The amount of time a session ID remains valid is configured under Security Controls => Session Settings in SFDC Setup. When it expires, the app will have to use the Refresh Token flow to request another Access Token from SFDC. To do this, the application will send a POST request to SFDC including the Refresh Token, the Consumer Key, and the Consumer Secret. SFDC will respond with a new Access Token.
NOTE: At no time does the application store the Username or Password of the individual logging into the app.
So, that’s it. I hope you’ve enjoyed this foray into the world of oAuth 2.0 and Salesforce.com.